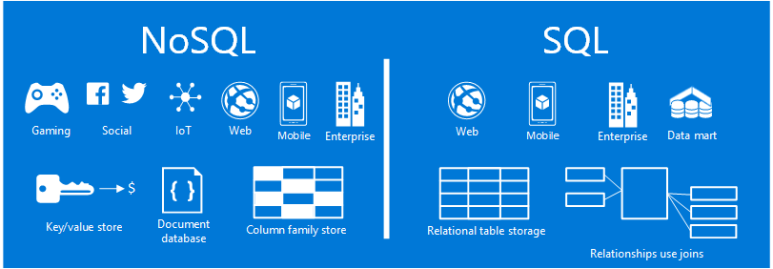
데이터베이스
|
관계형
|
비관계형
|
|
데이터 스토리지 행 및 열
|
데이터 스토리지 키값 문서 및 그래프
|
|
스키마 고정
|
스키마 동적
|
|
SQL 기반 쿼리
|
문서 수집에 집중
|
|
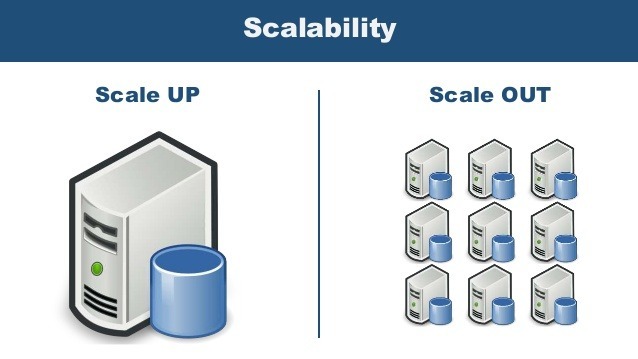
수직적 (scale up)
|
수평적 (scale out)
|
|
데이터 정합성
|
빠른 읽기 쓰기
|
비관계형 이전에는 Dataware House를 사용.
관계형 데이터베이스는 확장 시 downtime과 max limit 등의 단점이 있다.
때에 따라 다르지만 비관계형 데이터베이스는 어플리케이션 먼저 만들고 DB 구성한다.
요즘에는 비관계형으로 데이터를 받고 필요한 부분 관계형으로 저장한다.
비관계형은 partition tolerance 즉 분산형으로 만들었을 때 하나에 장애가 일어나도 다른 하나가 장애가 일어나지 않게 구축할 수 있다.
SQL 튜닝
요즘은 클라이언트의 충성도가 낮다 대체할 만한 것이 많기 때문인데, 조금만 느리거나 기능이 동작되지 않으면 이탈한다.
성능이란 사용자가 체감할 수 있는 수치적 증명 수준이다.
성능 저하 요인은 SQL/APP/DB design가 80%를 차지한다.
오픈소스 사용은 비용을 줄이는 목적 대신 성능의 제약이 있는데 이 부분을 튜닝으로 극복할 수 있다.
SQL은 정답이 없다 대신 좋은 쿼리는 있다.
SQL 튜닝의 목표는 결국 일의 양을 줄이는 것이다.
JOS 튜닝 방법론
Table Join(Nested Loop Join, Hash Join, Merge Join..) 어떤 조인 방식인가
Table Order(A > B > C > D, A > C > B > D..) 어떤 순서로 조인하는가
Table Scan (Full Table Scan, Index Scan..) 조인할 때 어떤 방식으로 스캔할 것인가
옵티마이저 소개
SQL 처리 과정
문법 오타 체크 > ASCII 변경 > HashFunction > Hash Value > 메모리 Shared Pool에서 동일 실행계획이 있는지 확인
1. 쿼리가 있다 > 실행계획을 재사용한다. Soft Parsing
2. 쿼리가 없다 > 옵티마이저가 실행계획을 세운다. (CBO 가성비, RBO) Hard Parsing > 메모리에 적재하고 실행한다.
Optimizer Statistics(옵티마이저 통계)는 데이터베이스 모든 오브젝트에 대한 자료를 모아 기술한 통계인데 이는 데이터 딕셔너리(Data Dictionary)에 저장되며 이 통계정보를 바탕으로 오라클 옵티마이저는 SQL 문장 실행을 위한 효율적인 실행계획을 만들어 낸다.
통계정보
비용 : 예상 일량 또는 시간
인덱스를 경유한 테이블 액세스 비용 : Single Block I/O COUNT
Full Scan에 의한 테이블 액세스 비용 : multiblock Block I/O COUNT
옵티마이저 힌트
오라클 이외의 밴더는 힌트의 강제성이 있으나 오라클은 예외
/*+ORDERED*/ From절에 기술된 테이블 순서대로 조인
/*+LEADING*/ From절과 상관없이 테이블 순서대로 지정
/*+ALL_ROWS*/ 마지막 출력될 행까지 최소한 자원 사용 (전체를 빨리 나오게)
/*+FIRST_ROWS*/ 첫 번째 행이 빠르게 반환
/*+RULE*/ 규칙기반 옵티마이저로 실행
/*+FULL*/ 테이블 전체 scan
/*+INDEX*/ Index range scan
/*+INDEX_DESC*/ 인덱스 구성된 컬럼 값의 내림차순으로 range scan
/*+INDEX_FFS*/ 인덱스 전체 scan
/*+INDEX_SS*/ 인덱스 skip scan
/*+USE_NL*/ Nested loop 방식으로 조인
/*+USE_HASH*/ Hash 방식으로 조인
/*+USE_MERGE*/ Sort Merge 방식으로 조인
/*+PARALLEL*/ 하나의 작업을 여러 개의 서버 프로세스가 동시에 병렬처리하도록 설정
/*+PARALLER_INDEX*/ 인덱스를 병렬처리하도록 설정
/*+USE_CONCAT*/ WHERE절 또는 IN 연산자를 분리 수행하고 결과 결합
/*+MERGE*/ /*+NO_MERGE*/ VIew의 처리가 메인 쿼리 병합되지 않을 때 강제로 MERGE 하도록
/*+UNNEST*/ /*+NO_UNNEST*/ 메인 쿼리와 서브 쿼리를 병합하여 조인 형태로 변환
/*+APPEND*/ insert 시 direct path 방식 수행(병렬 모드)
힌트는 웬만하면 안 쓰는 걸 권장한다 되도록 SQL에서 정리하자.
추가로 옵티마이저는 IN, BETWEEN을 싫어한다.
비용 기반 쿼리 변환 : 변환된 쿼리의 비용이 더 낮을 때만 그것을 사용하고 그렇지 않을 때는 원본 쿼리 그대로 두고 최적화를 수행한다.
|
Before
|
After
|
|
Sales_qty > 1200/12
|
Sales_qty > 100
|
|
Sales_qty*12 > 1200
|
No transformation
|
|
Job like 'SALESMAN'
|
Job = 'SALESMAN'
|
|
Job in ('C','M')
|
Job = 'C' or Job = 'M'
|
|
Sales_qty > ANY(:A,:B)
|
Sales_qty > :A or Sales_qty > :B
|
|
Where 100 > ANY(SELECT sal FROM emp
WHERE job='CLERK')
|
Where EXISTS (SELECT sal FROM emp
WHERE job='CLERK')
|
좌변 컬럼 수정 제어를 못한다.
존재 유무 체크만 할 경우 EXISTS를 사용한다. EXISTS는 true 혹은 false만 체크하고 메인 쿼리를 읽고 서브 쿼리를 읽는다.
|
Before
|
After
|
|
SELECT *
FROM emp e, dept d
WHERE e.deptno = 20
AND e.deptno=d.deptno
|
SELECT *
FROM emp e, dept d
WHERE d.deptno = 20
AND e.deptno=d.deptno
|
|
SELECT distinct e.empno, e.ename
FROM emp e, dept d
WHERE e.deptno = 20
AND e.deptno = d.deptno
|
SELECT
FROM emp e, dept d
WHERE e.deptno = 20
AND e.deptno = d.deptno
|
|
SELECT t1.x,v.z
FROM t1,t2, (select t3.z, t4.m
from t3,t4
where t3.k = t4.k
and t4.q = 5) v
WHERE t2.p = t1.p
AND t2.m = v.m;
|
SELECT t1.x,v.z
FROM t1,t2,t3,t4
WHERE t2.p = t1.p
AND t2.m=t4.m
AND t3.k =t4.k
AND t4.q = 5;
|
실행계획서
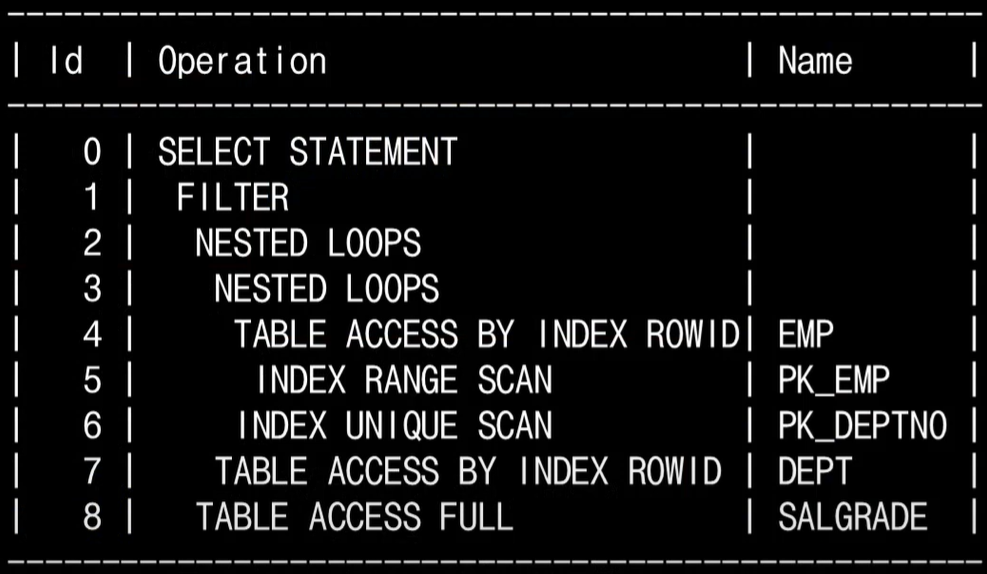
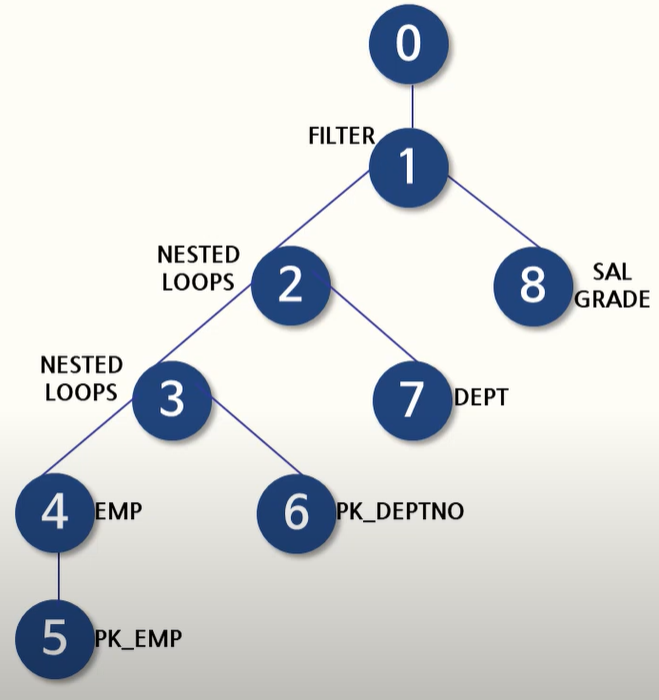
실행계획서를 통해 옵티마이저가 해야 할 일을 미리 해줌으로써 성능 향상의 기대도 해볼 수 있다.
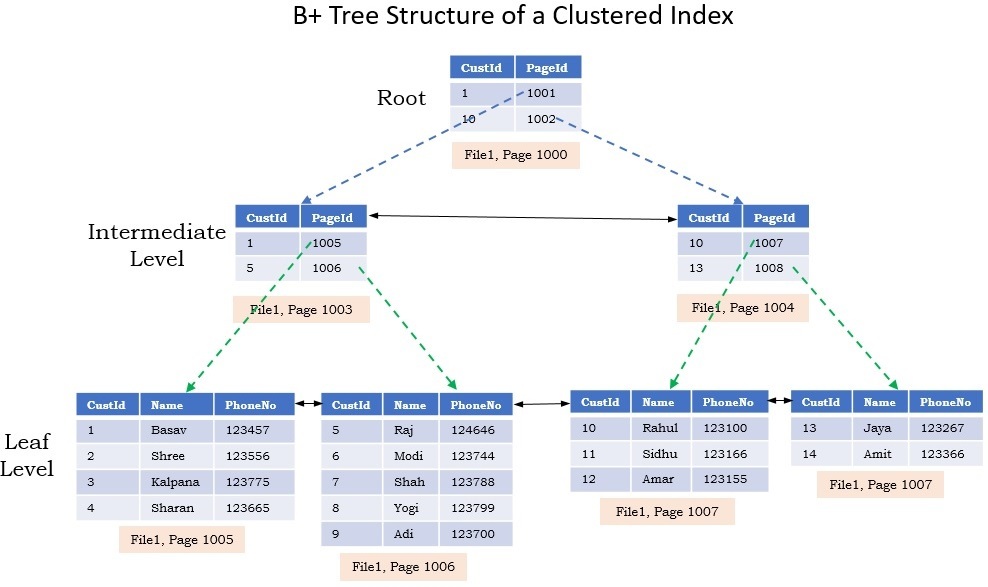
인덱스 종류
B*Tree Index : 가장 일반적인 기본 Index
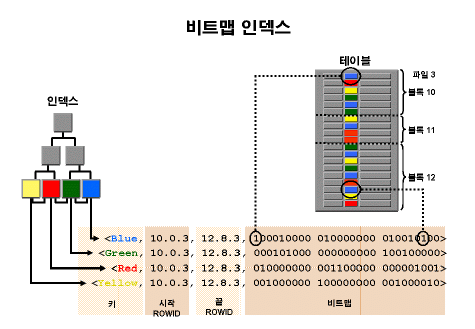
Bitmap index
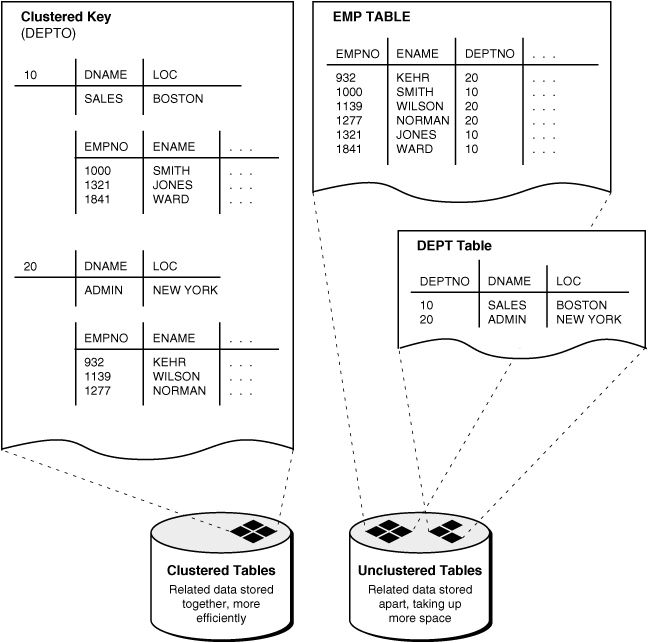
Cluster Index
랜덤 액세스
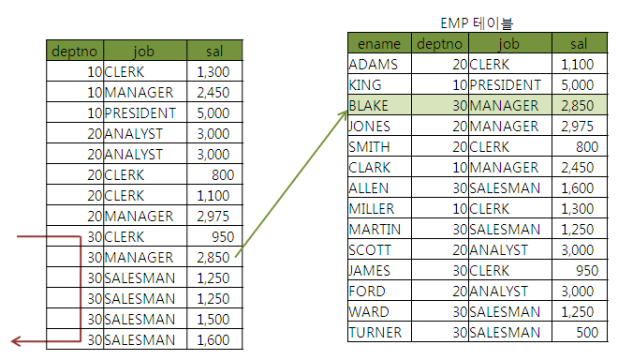
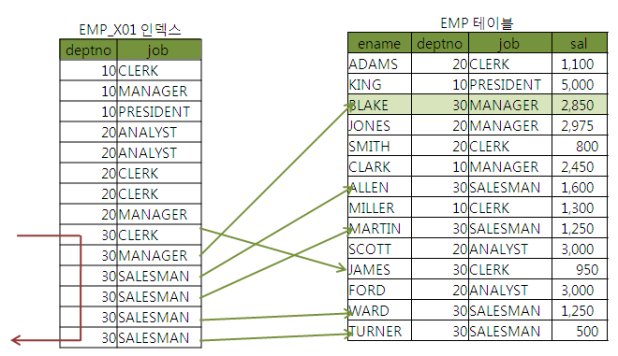
인덱스 구성을 deptno + sal에서 deptno + job + sal로 변경했을때 엑서스의 변화
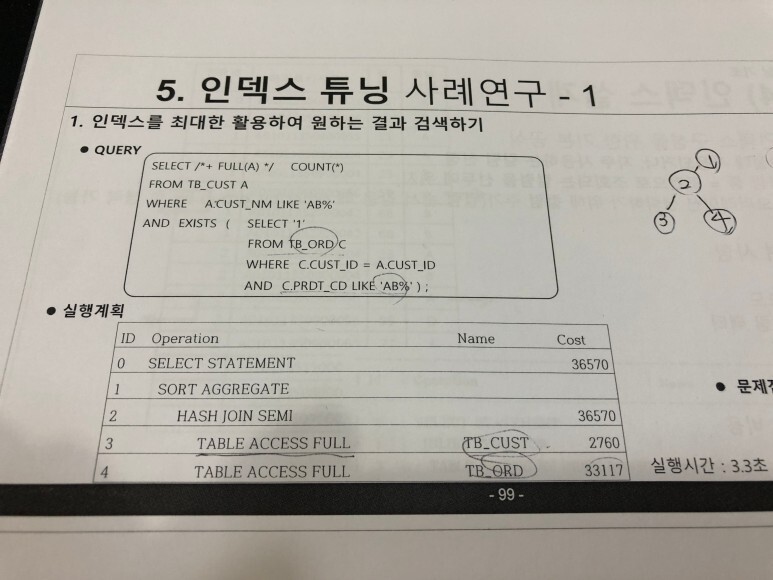
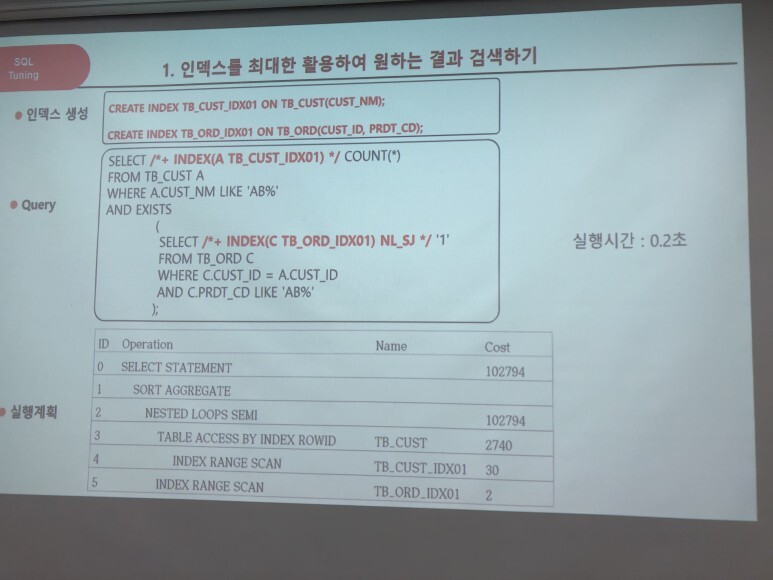





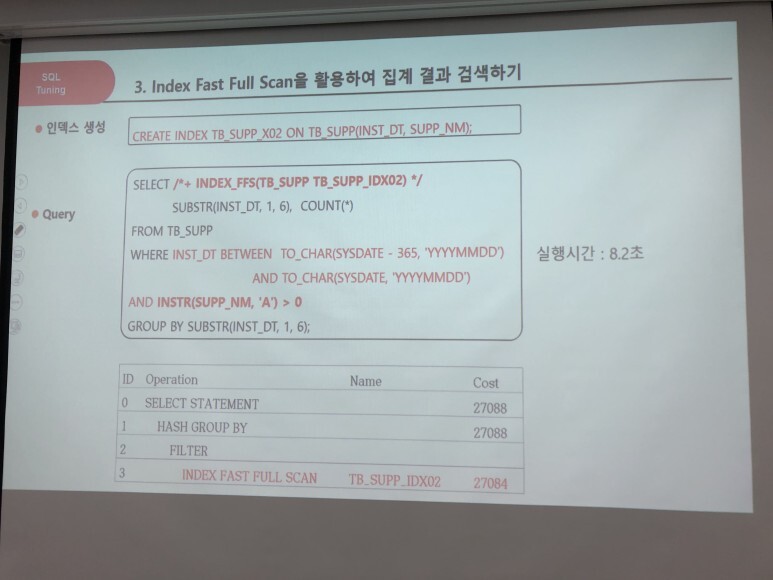

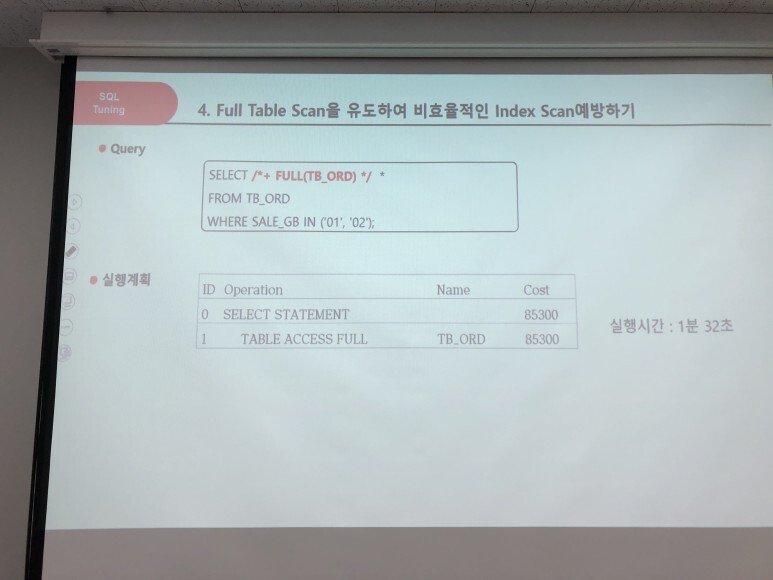
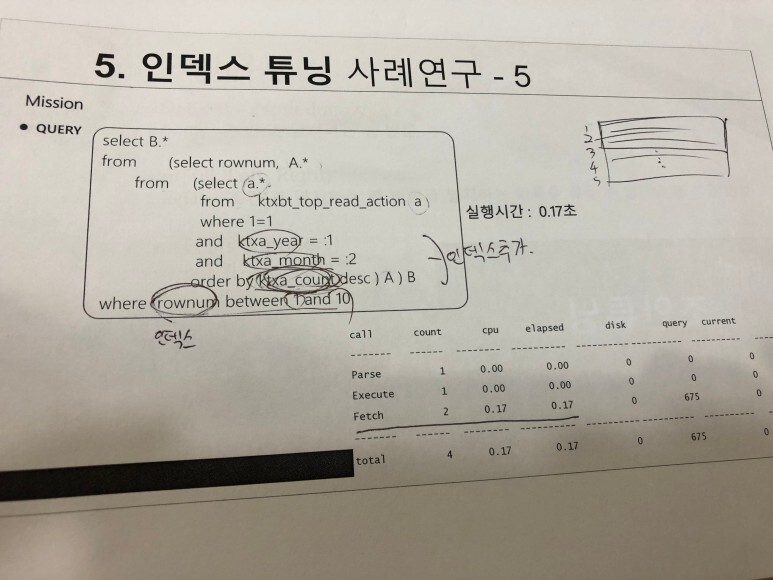
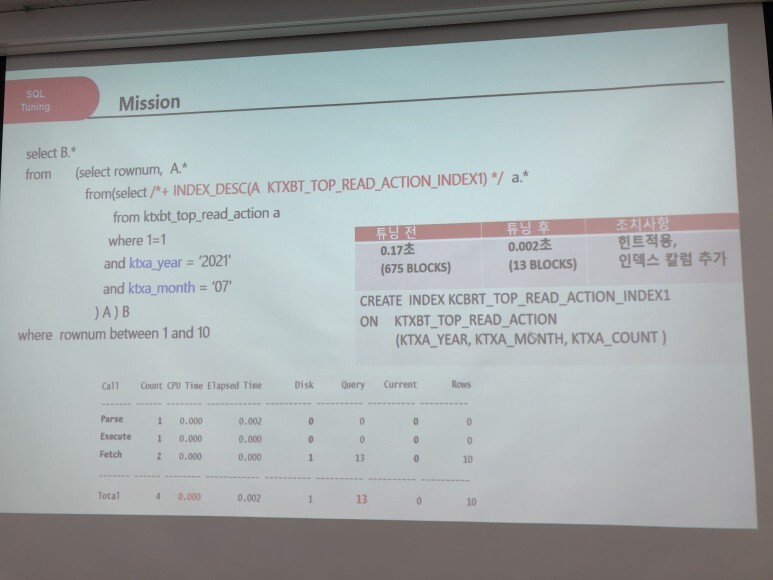
왼쪽 문제 오른쪽 스크린 답
위 사례는 해당 쿼리만 사용했을 때의 튜닝을 한 것이다 현실은 훨씬 더 많은 것들이 얽혀있고 복잡하게 구현되어 있다.
실제로 튜닝을 하는것은 간단한 문제가 아니고 성능 트레이드오프 발생을 항상 염두 해야 한다.
'이전자료 > 웹개발' 카테고리의 다른 글
| Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:x.x.x:compile 에러 (0) | 2022.01.19 |
|---|---|
| Vuejs Reactivity 이해하기 (0) | 2022.01.18 |
| SQL 튜닝 및 사례 연구 (조인 튜닝) (0) | 2022.01.18 |
| 자바스크립트 압축(uglifsjs) 및 복원(beautify) 하기 (0) | 2022.01.17 |
| node.js(express) .env로 DB정보 따로 관리하기 (0) | 2022.01.17 |